Le istituzioni finanziarie, i sistemi di prenotazione e altri operatori business-critical amano le "grandi macchine" di IBM per la loro affidabilità. Non c'è da stupirsi che la lettera z nel nome dei sistemi significhi Zero Downtime - zero downtime. Alla conferenza Hot Chips 33, l'azienda ha presentato una nuova generazione di processori z, che per la prima volta nella storia ha ricevuto il proprio nome Telum (dardo in latino). Il nome "arma" è stato scelto per un motivo: nella nuova architettura, IBM ha introdotto anche nuove soluzioni che non erano precedentemente utilizzate in System z, progettate, in particolare, per combattere le frodi.
Alcuni dei clienti chiave di IBM, grandi società finanziarie e banche, aspettano da tempo strumenti di intelligenza artificiale integrati, poiché i loro sistemi devono elaborare migliaia e migliaia di transazioni al secondo e farlo nel modo più affidabile possibile. Uno degli obiettivi nello sviluppo di Telum è stata l'introduzione di calcoli di inferenza che avvengono in tempo reale proprio durante l'elaborazione di una transazione e senza inviare alcun dato all'esterno del sistema.
Pertanto, l'acceleratore di inferenza in Telum è collegato direttamente al sottosistema della cache e utilizza tutti i processori z/Architecture e i meccanismi di protezione della memoria. E lui stesso porta anche una serie di approcci caratteristici di z. Pertanto, un "firmware" separato controlla il funzionamento dell'acceleratore, che può essere modificato per ottimizzare le attività di un particolare client. Viene eseguito su uno dei core e sull'acceleratore stesso, che comunica con questo core ed è responsabile dell'accesso alla memoria e alla cache, della sicurezza e dell'integrità dei dati e della gestione dei calcoli effettivi.
L'acceleratore include due tipi di motori. Il primo ha 128 blocchi SIMD per operazioni MAC con dati FP16 ed è necessario per la moltiplicazione e la convoluzione di matrici. Il secondo ha solo 32 blocchi SIMD, ma può funzionare con dati FP16 / FP32 ed è ottimizzato per funzioni di attivazione di rete e altre attività più complesse. Sono completati da un blocco di memoria ultraveloce (scratchpad) e da un motore IO "intelligente" responsabile dello spostamento e della preparazione dei dati, che può riformattarli al volo.
Scratchpad è collegato a un blocco che scarica i dati dalla cache L2 e restituisce i risultati dei calcoli. IBM sottolinea separatamente che la presenza di un acceleratore AI dedicato consente l'uso di blocchi SIMD convenzionali nei core in parallelo, suggerendo chiaramente l'AVX-512 VNNI. Tuttavia, Sapphire Rapids ora ha anche un'unità AMX separata nel core, che è, tuttavia, con funzionalità più modeste.
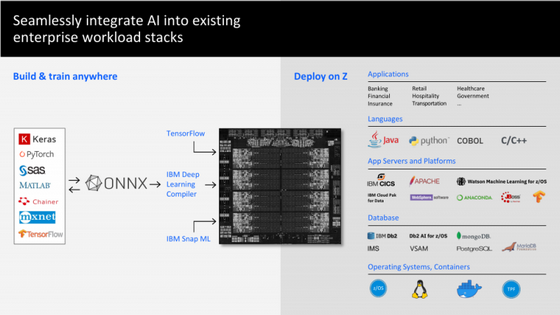
È possibile accedere all'acceleratore dallo spazio utente, anche in un ambiente virtualizzato. Per lavorare con il nuovo acceleratore, l'azienda offre IBM Deep Learning Compiler, che aiuterà a ottimizzare i modelli ONNX importati. C'è anche il supporto out-of-the-box per TensorFlow, IBM Snap ML e una gamma di strumenti di sviluppo popolari. C'è un acceleratore AI per processore con prestazioni di oltre 6 teraflop FP16.
Sul modello di test RNN per la protezione contro le frodi, il chip può eseguire 116 mila operazioni di inferenza con una latenza entro 1,1 ms e per un sistema di 32 processori questa cifra è già di 3,6 milioni di operazioni di inferenza e la latenza aumenta. 1,2 ms. Oltre all'acceleratore AI, c'è anche un acceleratore (de-)compressione (gzip) comune a tutti i core + ogni core ha anche un motore per CSMP. Bene, anche gli acceleratori per l'ordinamento e la crittografia non sono andati da nessuna parte.
Centinaia di meccanismi diversi per controllare e ricontrollare l'operatività sono responsabili dell'affidabilità. Quindi, ad esempio, i registri e la cache vengono duplicati, consentendo in caso di guasto dello yal di effettuare un riavvio completo e continuare l'esecuzione dei task esattamente dal punto in cui è stata interrotta. E per la RAM, che è necessariamente crittografata, viene utilizzata la modalità Redundant Array of Memory (RAIM), una sorta di array RAID, in cui una linea di cache viene "spalmata" tra otto moduli contemporaneamente.
Telum, ereditando molto dal suo predecessore z15, è ancora radicalmente diverso da esso. Il processore contiene otto core con supporto per l'esecuzione "intelligente" di deep out-of-order e SMT2, operando a una frequenza di oltre 5 GHz. Ogni core si basa su 32 MB di cache L2, quindi le altre CPU moderne sembrano noiose sullo sfondo. Ma non è così semplice.
Le cache comunicano tra loro tramite un ring bus bidirezionale con una larghezza di banda superiore a 320 GB/s, formando così una cache L3 virtuale con un volume di 256 MB e con una latenza media di 12 ns. Ciascun chip Telum può contenere uno (SCM) o due (DCM) processori. E in un nodo possono esserci fino a quattro chip, ovvero fino a otto CPU, combinate secondo lo schema ciascuno con la stessa velocità di 320 GB / s.
Pertanto, nell'ambito del nodo, viene formata una cache L4 virtuale con un volume di 2 GB. La topologia piatta delle cache, secondo IBM, fornisce nuovi processori con una latenza inferiore rispetto allo z15. È possibile scalare fino a 32 processori, ma i singoli nodi sono collegati da più connessioni a "soli" 45 GB/s per tratta.
IBM sta segnalando un miglioramento delle prestazioni del 40% rispetto allo z15 per socket. Telum contiene 22 miliardi di transistor e ha un TDP di 400 W in modalità normale.
2021-08-24 04:55:13
Autore: Vitalii Babkin