Les institutions financières, les systèmes de réservation et d'autres opérateurs critiques apprécient les « grosses machines » d'IBM pour leur fiabilité. Pas étonnant que la lettre z dans le nom des systèmes signifie Zero Downtime - zéro temps d'arrêt. Lors de la conférence Hot Chips 33, la société a dévoilé une nouvelle génération de processeurs z, qui, pour la première fois dans l'histoire, a reçu son propre nom Telum (fléchette en latin). Le nom « arme » a été choisi pour une raison : dans la nouvelle architecture, IBM a également introduit de nouvelles solutions qui n'étaient pas utilisées auparavant dans System z, conçues notamment pour lutter contre la fraude.
Certains des principaux clients d'IBM - les grandes sociétés financières et les banques - attendent depuis longtemps des outils d'IA intégrés, car leurs systèmes doivent traiter des milliers et des milliers de transactions par seconde, et le faire de la manière la plus fiable possible. L'un des objectifs du développement de Telum était l'introduction de calculs d'inférence qui se produisent en temps réel pendant le traitement d'une transaction et sans envoyer de données en dehors du système.
Par conséquent, l'accélérateur d'inférence de Telum est connecté directement au sous-système de cache et utilise tous les mécanismes de protection du processeur et de la mémoire z/Architecture. Et lui-même porte également un certain nombre d'approches caractéristiques de z. Ainsi, un "firmware" séparé contrôle le fonctionnement de l'accélérateur, qui peut être modifié pour optimiser les tâches d'un client particulier. Il est exécuté sur l'un des cœurs et l'accélérateur lui-même, qui communique avec ce cœur, et est responsable de l'accès à la mémoire et au cache, de la sécurité et de l'intégrité des données, et de la gestion des calculs réels.
L'accélérateur comprend deux types de moteurs. Le premier a 128 blocs SIMD pour les opérations MAC avec des données FP16 et est nécessaire pour la multiplication et la convolution matricielles. Le second n'a que 32 blocs SIMD, mais il peut fonctionner avec des données FP16 / FP32 et est optimisé pour les fonctions d'activation de réseau et d'autres tâches plus complexes. Ils sont complétés par un bloc de mémoire ultra-rapide (scratchpad) et un moteur IO "intelligent" chargé de déplacer et de préparer les données, qui peut les reformater à la volée.
Scratchpad est connecté à un bloc qui télécharge les données du cache L2 et renvoie les résultats des calculs. IBM souligne séparément que la présence d'un accélérateur d'IA dédié permet l'utilisation de blocs SIMD conventionnels dans les cœurs en parallèle, faisant clairement allusion à l'AVX-512 VNNI. Cependant, Sapphire Rapids dispose désormais également d'une unité AMX distincte dans le noyau, qui est cependant plus modeste dans ses fonctionnalités.
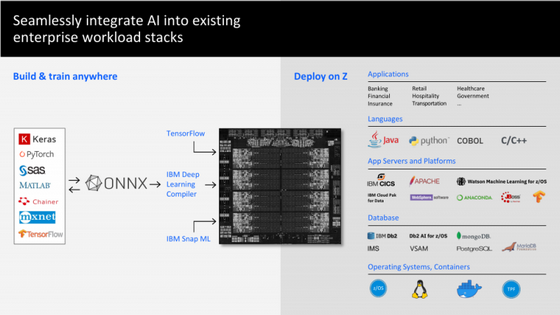
L'accélérateur est accessible depuis l'espace utilisateur, y compris dans un environnement virtualisé. Pour travailler avec le nouvel accélérateur, la société propose le compilateur IBM Deep Learning, qui aidera à optimiser les modèles ONNX importés. Il existe également une prise en charge prête à l'emploi pour TensorFlow, IBM Snap ML et une gamme d'outils de développement populaires. Il y a un accélérateur AI par processeur avec une performance de plus de 6 téraflops FP16.
Sur le modèle de test RNN pour la protection contre la fraude, la puce peut effectuer 116 000 opérations d'inférence avec une latence inférieure à 1,1 ms, et pour un système de 32 processeurs, ce chiffre est déjà de 3,6 millions d'opérations d'inférence, et la latence augmente aussi bas que 1,2 milliseconde. En plus de l'accélérateur AI, il existe également un accélérateur de (dé-)compression (gzip) commun à tous les cœurs + chaque cœur dispose également d'un moteur pour CSMP. Eh bien, les accélérateurs de tri et de chiffrement ne sont pas allés nulle part non plus.
Des centaines de mécanismes différents pour vérifier et revérifier l'opérabilité sont responsables de la fiabilité. Ainsi, par exemple, les registres et le cache sont dupliqués, permettant en cas de panne du yal de lui faire un redémarrage complet et de continuer l'exécution des tâches exactement à partir de l'endroit où il a été interrompu. Et pour la RAM, qui est nécessairement cryptée, on utilise le mode Redundant Array of Memory (RAIM), une sorte de RAID-array, où une ligne de cache est « étalée » entre huit modules à la fois.
Telum, héritant beaucoup de son prédécesseur z15, en est encore radicalement différent. Le processeur contient huit cœurs prenant en charge l'exécution "intelligente" profonde dans le désordre et SMT2, fonctionnant à une fréquence de plus de 5 GHz. Chaque cœur repose sur 32 Mo de cache L2, de sorte que les autres processeurs modernes semblent ternes par rapport à son arrière-plan. Mais ce n'est pas si simple.
Les caches communiquent entre eux via un bus en anneau bidirectionnel avec une bande passante de plus de 320 Go/s, formant ainsi un cache L3 virtuel d'un volume de 256 Mo et avec une latence moyenne de 12 ns. Chaque puce Telum peut contenir un (SCM) ou deux (DCM) processeurs. Et dans un nœud, il peut y avoir jusqu'à quatre puces, c'est-à-dire jusqu'à huit processeurs, combinés selon le schéma chacun-s-chacun avec la même vitesse de 320 Go / s.
Ainsi, dans le cadre du nœud, un cache L4 virtuel d'un volume de 2 Go est formé. La topologie plate des caches, selon IBM, fournit de nouveaux processeurs avec une latence inférieure par rapport au z15. La mise à l'échelle jusqu'à 32 processeurs est possible, mais les nœuds individuels sont reliés par plusieurs connexions à "seulement" 45 Go / s dans chaque sens.
IBM signale une amélioration des performances de 40 % par rapport au z15 par socket. Telum contient 22 milliards de transistors et a un TDP de 400W en mode normal.
2021-08-24 04:55:13
Auteur: Vitalii Babkin