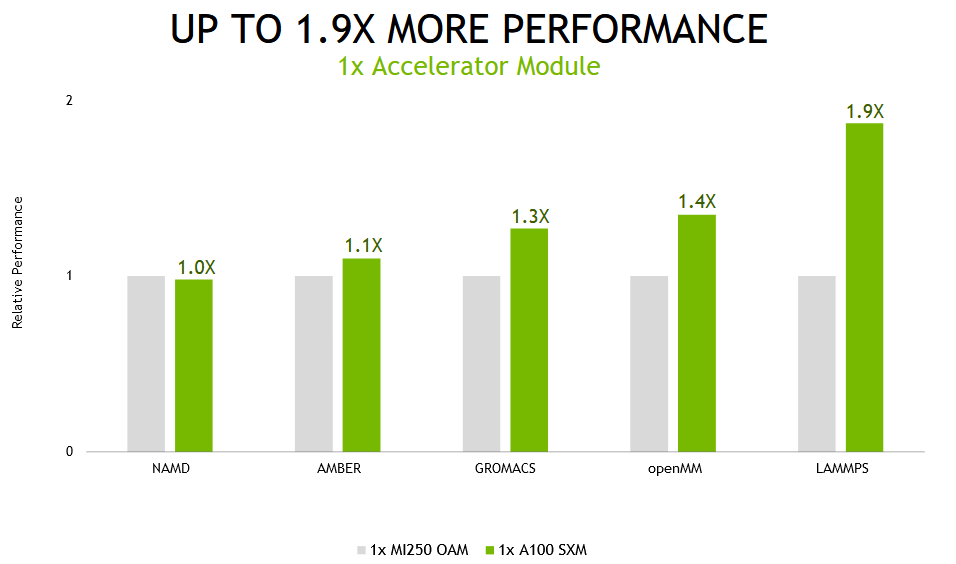
Interessantes Material wurde im Nvidia-Blog veröffentlicht. Es vergleicht die Leistung spezialisierter Beschleuniger, die auf das HPC-High-Performance-Computing-Segment ausgerichtet sind. Üblicherweise liegen uns nur technische Spezifikationen und rohe Leistungsdaten solcher Geräte vor. In diesem Fall versuchte Nvidia, das Potenzial von Beschleunigern unter realen Bedingungen mit gängigen Workloads im Rechenzentrum zu vergleichen, darunter LAMMPS, NAMD, openMM, GROMACS und AMBER.
Vergleich von Nvidia A100 und AMD Instinct MI250 in Konfigurationen mit einem und vier Beschleunigern. Der Unterschied zwischen den Beschleunigern hängt von den Aufgaben ab, irgendwo sind es 10 %, und irgendwo ist die Nvidia A100 doppelt so schnell wie die Konkurrenz. Die folgenden Grafiken zeigen die Effizienzkoeffizienten von Beschleunigern bei verschiedenen Lasten.
Auch bei der Energieeffizienz gewinnt Nvidias Lösung. Bei LAMMPS-Workloads ist der Leistungsgewinn pro Watt bis zu 2,8-mal besser zugunsten des Nvidia A100.
Der Nvidia A100-Beschleuniger wurde erstmals im Jahr 2020 angekündigt. Es verwendet eine massive Ampere-GPU mit 54 Milliarden Transistoren. Der A100 verfügt über 6912 Stream-Prozessoren, 432 Tensorkerne und 40 GB HBM2-Speicher mit einem 5120-Bit-Bus. Das Herzstück des AMD Instinct MI250-Beschleunigers ist eine GPU mit dem Codenamen Aldebaran mit 13312 Stream-Prozessoren plus 128 GB HBM2E-Speicher. AMD hat auch ein Spitzenmodell AMD Instinct MI250X mit einer großen Anzahl von Recheneinheiten. Aber die Ergebnisse des älteren Nvidia A100-Beschleunigers sind immer noch beeindruckend. Gleichzeitig hat Nvidia bereits einen H100-Beschleuniger der neuen Generation auf Basis der Hopper-Architektur angekündigt.
2022-06-04 08:21:08
Autor: Vitalii Babkin