Tesla ha già annunciato il proprio processore D1, creato nei laboratori dell'azienda, che diventerà la base del supercomputer Dojo AI. Abbiamo bisogno di un sistema del genere per creare un campo di addestramento virtuale per il pilota AI, ricreando nel dettaglio situazioni reali sulle strade. Naturalmente, un simulatore del genere richiede un'enorme potenza di calcolo: nel nostro mondo, le condizioni del traffico sono molto complesse, mutevoli e includono molti fattori e variabili.
Fino a poco tempo non si sapeva molto di Dojo e D1, ma alla conferenza Hot Chips 34 sono state rivelate molte cose interessanti sull'architettura, il design e le capacità di questa soluzione Tesla. La presentazione è stata ospitata da Emil Talpes, che in precedenza ha lavorato in AMD per 17 anni sulla progettazione di processori per server. Lui, come molti altri importanti sviluppatori, sta attualmente lavorando in Tesla per creare e migliorare l'hardware dell'azienda.
L'idea principale di D1 era la scalabilità, quindi all'inizio dello sviluppo di un nuovo chip, i creatori hanno attivamente riconsiderato il ruolo di concetti tradizionali come coerenza, memoria virtuale, ecc. - non tutti i meccanismi scalano nel migliore dei modi quando si tratta di costruire un sistema informatico davvero grande. Invece, è stata data la preferenza a una rete di archiviazione distribuita basata su SRAM, per la quale è stata creata un'interconnessione che era un ordine di grandezza in anticipo rispetto alle implementazioni esistenti nei sistemi di calcolo distribuito.
La base del processore Tesla era un core di calcolo intero, basato su alcune istruzioni del set RISC-V, ma integrato da un gran numero di istruzioni proprietarie ottimizzate per i requisiti dei core di apprendimento automatico utilizzati dall'azienda. Il blocco di matematica vettoriale è stato creato quasi da zero, secondo gli sviluppatori.
Il set di istruzioni Dojo include istruzioni scalari, a matrice e SIMD, nonché primitive specifiche per spostare i dati dalla memoria locale alla memoria remota, nonché semafori con barriere: queste ultime sono necessarie per coordinare il lavoro di memoria in tutto il sistema. Per quanto riguarda le istruzioni specifiche per il machine learning, sono implementate in Dojo nell'hardware.
Il primogenito della serie, il chip D1, non è un acceleratore di per sé: l'azienda lo considera un processore multiuso ad alte prestazioni che non necessita di acceleratori specifici. Ogni unità di calcolo Dojo è rappresentata da un singolo core D1 con memoria locale e interfacce I/O. Questo è un kernel superscalare a 64 bit.
Inoltre, il kernel supporta il multithreading (SMT4), progettato per aumentare le prestazioni per clock (piuttosto che isolare attività diverse l'una dall'altra), quindi questa implementazione SMT non supporta la memoria virtuale e i meccanismi di protezione hanno funzionalità piuttosto limitate. Uno stack software specializzato e un software proprietario sono responsabili della gestione delle risorse del Dojo.
Il kernel a 64 bit ha una finestra di recupero di 32 byte, che può contenere fino a 8 istruzioni, che corrisponde alla larghezza del decoder. Lui, a sua volta, può elaborare due thread per ciclo. Il risultato va agli scheduler, che lo inviano a un'unità di calcolo intera (due ALU) oa un'unità vettoriale (64 byte di larghezza SIMD + moltiplicazione di matrici 8×8×4).
Ogni core D1 ha 1,25 MB di SRAM. Questa memoria non è una cache, ma è in grado di caricare dati ad una velocità di 400 GB/s e di archiviare ad una velocità di 270 GB/s, e, come già accennato, nel chip sono implementate apposite istruzioni che consentono di lavorare con i dati in altri core Dojo. Per questo, il blocco SRAM ha i suoi meccanismi, in modo che lavorare con la memoria remota non richieda operazioni aggiuntive.
Per quanto riguarda i formati di dati supportati, il blocco scalare supporta formati interi da 8 a 64 bit, mentre i blocchi vettoriali e matrice supportano un'ampia gamma di formati in virgola mobile, inclusi calcoli a precisione mista: FP32, BF16, CFP16 e CFP8. Gli sviluppatori D1 sono arrivati a utilizzare un intero set di rappresentazioni di dati configurabili a 8 e 16 bit: il compilatore Dojo può modificare dinamicamente i valori della mantissa e dell'esponente, in modo che il sistema possa utilizzare fino a 16 diversi formati vettoriali , purché non cambi.
Come già accennato, la topologia D1 utilizza una struttura mesh in cui ogni 12 core sono combinati in un blocco logico. L'intero chip D1 è un array di 18 × 20 core, ma sono disponibili solo 354 core su 360 presenti sul chip. Lo stesso die da 645 mm2 è prodotto negli stabilimenti di TSMC utilizzando una tecnologia di processo a 7 nm. La frequenza di clock è di 2 GHz, la quantità totale di SRAM è di 440 MB.
Il processore D1 sviluppa 362 Tflop in modalità BF16 / CFP8, in modalità FP32 questa cifra scende a 22 Tflops. La modalità FP64 non è supportata dai blocchi vettoriali D1, quindi questo processore non è adatto a molti carichi di lavoro HPC tradizionali. Ma Tesla ha costruito il D1 per uso interno, quindi non si preoccupa davvero della compatibilità. Tuttavia, nelle nuove generazioni, D2 o D3, tale supporto può apparire se si adatta agli obiettivi dell'azienda.
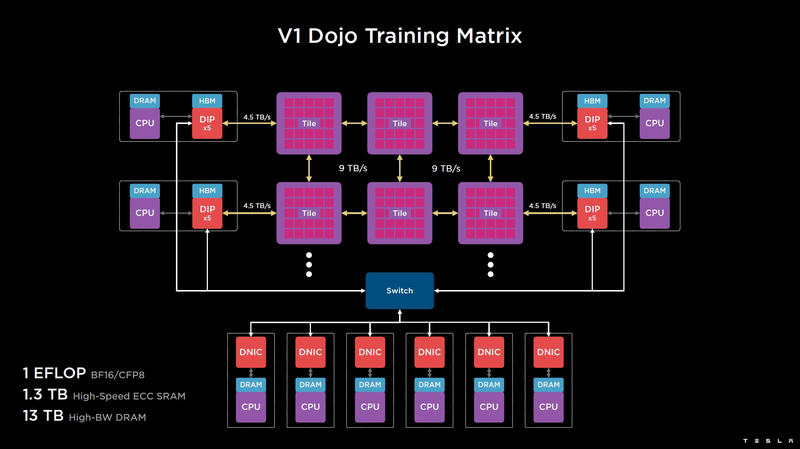
Ogni die D1 ha un'interfaccia SerDes esterna a 576 bit con prestazioni combinate di 8 TB/s su tutti e quattro i lati, quindi non diventerà un collo di bottiglia quando si collega D1. Questa interfaccia combina i cristalli in un'unica matrice 5x5, tale matrice di 25 cristalli D1 è chiamata tessera di allenamento Dojo.
Questa piastrella è progettata come un modulo termoelettromeccanico completo, dotato di un'interfaccia esterna con una larghezza di banda di 4,5 TB / s per lato, con un totale di 11 GB di SRAM, nonché un proprio sistema di alimentazione da 15 kW. La potenza di elaborazione di una tessera Dojo è di 9 PFlops nel formato BF16/CFP8. A questo livello di consumo energetico, il Dojo può essere raffreddato solo a liquido.
Le piastrelle possono essere combinate in matrici ancora più produttive, ma non è del tutto chiaro come sia organizzato fisicamente il supercomputer Tesla. Per comunicare con il mondo esterno, vengono utilizzati i blocchi DIP - Dojo Interface Processors. Questi sono processori di interfaccia attraverso i quali le tile comunicano con i sistemi host e sono assegnate funzioni di controllo, archiviazione di array di dati, ecc. Ciascun DIP non esegue solo funzioni IO, ma contiene anche 32 GB di memoria HBM (non specificata, HBM2e o HBM3).
DIP utilizza il suo intero protocollo di trasporto (Tesla Transport Protocol, TTP), sviluppato da Tesla e fornendo un throughput di 900 GB / s e su Ethernet - 50 GB / s. L'interfaccia esterna delle schede è PCI Express 4.0 e ciascuna scheda di interfaccia è dotata di una coppia di DIP. Ci sono 5 DIP installati su ciascun lato di ogni fila di piastrelle, che offre una velocità fino a 4,5 TB / s dalle pile HBM alla piastrella.
Nei casi in cui l'accesso da piastrella a piastrella nell'intero sistema richieda troppi hop (fino a 30 in caso di accesso da bordo a bordo), il sistema può utilizzare DIP collegati esternamente da una fat tree network da 400 GbE, riducendo così il numero di salti a un massimo di quattro. Il throughput ne risente in questo caso, ma la latenza vince, il che è più importante in alcuni scenari.
Nella versione base, il supercomputer Dojo V1 produce 1 Eflop in modalità BF16 / CFP8 e può caricare modelli fino a 1,3 TB direttamente nella SRAM, altri 13 TB di dati possono essere archiviati negli assiemi DIP HBM. Va notato che lo spazio SRAM nell'intero sistema Dojo utilizza un singolo indirizzamento flat. La versione in scala reale di Dojo avrà prestazioni fino a 20 eflops.
Non si sa quanto sforzo l'azienda avrà bisogno per lanciare un mostro del genere e, soprattutto, fornirgli un software funzionante e utile, ma ovviamente molto. Il sistema è noto per essere compatibile con PyTorch. Tesla sta attualmente ottenendo chip D1 già pronti da TSMC. Nel frattempo, l'azienda si sta accontentando del più grande supercomputer NVIDIA AI installato al mondo.
2022-09-06 07:41:21
Autore: Vitalii Babkin