Tesla hat bereits einen eigenen D1-Prozessor angekündigt, der in den Labors des Unternehmens entwickelt wurde und die Grundlage des KI-Supercomputers Dojo werden wird. Wir brauchen ein solches System, um dem KI-Fahrer ein virtuelles Trainingsgelände zu schaffen, das reale Situationen auf der Straße detailgetreu nachbildet. Natürlich erfordert ein solcher Simulator enorme Rechenleistung: In unserer Welt sind die Verkehrsbedingungen sehr komplex, veränderlich und beinhalten viele Faktoren und Variablen.
Bis vor kurzem war nicht viel über Dojo und D1 bekannt, aber auf der Hot Chips 34-Konferenz wurden viele interessante Dinge über die Architektur, das Design und die Fähigkeiten dieser Tesla-Lösung enthüllt. Moderiert wurde die Präsentation von Emil Talpes, der zuvor 17 Jahre lang bei AMD im Bereich Serverprozessordesign gearbeitet hat. Er arbeitet derzeit wie eine Reihe anderer prominenter Entwickler bei Tesla, um die Hardware des Unternehmens zu entwickeln und zu verbessern.
Die Hauptidee von D1 war die Skalierbarkeit, daher haben die Entwickler zu Beginn der Entwicklung eines neuen Chips aktiv die Rolle traditioneller Konzepte wie Kohärenz, virtueller Speicher usw. überdacht. - Nicht alle Mechanismen lassen sich optimal skalieren, wenn es darum geht, ein wirklich großes Computersystem aufzubauen. Stattdessen wurde einem verteilten Speichernetzwerk auf SRAM-Basis der Vorzug gegeben, für das eine Verbindung geschaffen wurde, die bestehenden Implementierungen in verteilten Computersystemen um eine Größenordnung voraus war.
Die Basis des Tesla-Prozessors war ein Integer-Rechenkern, basierend auf einigen Anweisungen aus dem RISC-V-Set, aber ergänzt durch eine Vielzahl proprietärer Anweisungen, die für die Anforderungen der vom Unternehmen verwendeten Machine-Learning-Kerne optimiert wurden. Der Vektor-Mathematik-Block wurde laut den Entwicklern fast von Grund auf neu erstellt.
Der Dojo-Befehlssatz umfasst Skalar-, Matrix- und SIMD-Befehle sowie spezifische Grundelemente zum Verschieben von Daten aus dem lokalen Speicher in den entfernten Speicher sowie Semaphoren mit Barrieren – letztere sind erforderlich, um die Speicherarbeit im gesamten System zu koordinieren. Die spezifischen Anweisungen für maschinelles Lernen werden in Dojo in Hardware implementiert.
Der Erstgeborene der Serie, der D1-Chip, ist per se kein Beschleuniger - das Unternehmen betrachtet ihn als leistungsstarken Allzweckprozessor, der keine speziellen Beschleuniger benötigt. Jede Dojo-Recheneinheit wird durch einen einzelnen D1-Kern mit lokalem Speicher und E/A-Schnittstellen dargestellt. Dies ist ein superskalarer 64-Bit-Kernel.
Darüber hinaus unterstützt der Kernel Multithreading (SMT4), das darauf ausgelegt ist, die Leistung pro Takt zu erhöhen (anstatt verschiedene Aufgaben voneinander zu isolieren), sodass diese SMT-Implementierung keinen virtuellen Speicher unterstützt und Schutzmechanismen in ihrer Funktionalität eher eingeschränkt sind. Ein spezialisierter Software-Stack und proprietäre Software sind für die Verwaltung der Dojo-Ressourcen verantwortlich.
Der 64-Bit-Kernel hat ein 32-Byte-Fetch-Fenster, das bis zu 8 Anweisungen enthalten kann, was der Breite des Decoders entspricht. Er wiederum kann zwei Threads pro Zyklus bearbeiten. Das Ergebnis geht an die Scheduler, die es an eine ganzzahlige Berechnungseinheit (zwei ALUs) oder eine Vektoreinheit (64 Byte breite SIMD + 8 × 8 × 4-Matrixmultiplikation) senden.
Jeder D1-Kern hat 1,25 MB SRAM. Dieser Speicher ist kein Cache, sondern kann Daten mit einer Geschwindigkeit von 400 GB / s laden und mit einer Geschwindigkeit von 270 GB / s speichern. Wie bereits erwähnt, sind im Chip spezielle Anweisungen implementiert, mit denen Sie arbeiten können mit Daten in anderen Dojo-Kernen. Der SRAM-Baustein verfügt hierfür über eigene Mechanismen, so dass das Arbeiten mit Remote-Speicher keine zusätzlichen Operationen erfordert.
Was die unterstützten Datenformate betrifft, unterstützt der Skalarblock ganzzahlige Formate von 8 bis 64 Bit, während die Vektor- und Matrixblöcke eine breite Palette von Gleitkommaformaten unterstützen, einschließlich Berechnungen mit gemischter Genauigkeit: FP32, BF16, CFP16 und CFP8. Die D1-Entwickler kamen dazu, einen ganzen Satz konfigurierbarer 8- und 16-Bit-Datendarstellungen zu verwenden – der Dojo-Compiler kann die Werte von Mantisse und Exponent dynamisch ändern, sodass das System bis zu 16 verschiedene Vektorformate verwenden kann , solange es sich nicht ändert.
Wie bereits erwähnt, verwendet die D1-Topologie eine Mesh-Struktur, bei der alle 12 Kerne zu einem logischen Block zusammengefasst werden. Der gesamte D1-Chip ist ein Array von 18 × 20 Kernen, aber nur 354 von 360 auf dem Chip vorhandenen Kernen sind verfügbar. Der 645-mm2-Die selbst wird in den Einrichtungen von TSMC unter Verwendung einer 7-nm-Prozesstechnologie hergestellt. Die Taktfrequenz beträgt 2 GHz, die Gesamtmenge an SRAM beträgt 440 MB.
Der D1-Prozessor entwickelt im BF16 / CFP8-Modus 362 Tflops, im FP32-Modus sinkt diese Zahl auf 22 Tflops. Der FP64-Modus wird von D1-Vektorblöcken nicht unterstützt, daher ist dieser Prozessor für viele herkömmliche HPC-Workloads nicht geeignet. Aber Tesla hat das D1 für den internen Gebrauch gebaut, also kümmert es sich nicht wirklich um Kompatibilität. In neuen Generationen, D2 oder D3, kann eine solche Unterstützung jedoch erscheinen, wenn sie den Zielen des Unternehmens entspricht.
Jeder D1-Die verfügt über eine externe 576-Bit-SerDes-Schnittstelle mit einer kombinierten Leistung von 8 TB/s auf allen vier Seiten, sodass es beim Anschluss von D1 nicht zu einem Engpass wird. Diese Schnittstelle kombiniert die Kristalle zu einer einzigen 5x5-Matrix, eine solche Matrix aus 25 D1-Kristallen wird als Dojo-Trainingsplättchen bezeichnet.
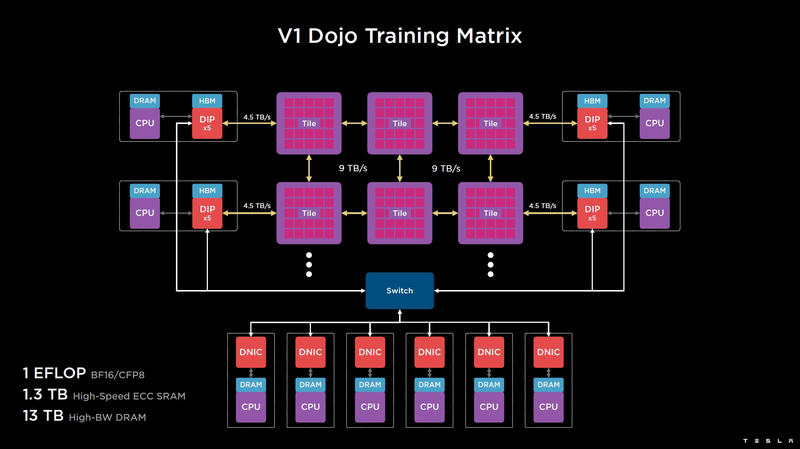
Diese Kachel ist als komplettes thermo-elektro-mechanisches Modul konzipiert und verfügt über eine externe Schnittstelle mit einer Bandbreite von 4,5 TB / s pro Seite, mit insgesamt 11 GB SRAM sowie einem eigenen 15-kW-Stromversorgungssystem. Die Rechenleistung einer Dojo-Kachel beträgt 9 PFlops im BF16/CFP8-Format. Bei dieser Leistungsaufnahme kann das Dojo nur flüssigkeitsgekühlt werden.
Kacheln können zu noch produktiveren Matrizen kombiniert werden, aber wie genau der Tesla-Supercomputer physisch organisiert ist, ist nicht ganz klar. Zur Kommunikation mit der Außenwelt werden DIP-Blöcke verwendet - Dojo Interface Processors. Dies sind Schnittstellenprozessoren, über die Kacheln mit Hostsystemen kommunizieren und denen Steuerfunktionen, Speicherung von Datenarrays usw. zugewiesen werden. Jeder DIP führt nicht nur IO-Funktionen aus, sondern enthält auch 32 GB HBM-Speicher (nicht spezifiziert, HBM2e oder HBM3).
DIP verwendet sein gesamtes Transportprotokoll (Tesla Transport Protocol, TTP), das von Tesla entwickelt wurde und einen Durchsatz von 900 GB / s und über Ethernet 50 GB / s bietet. Die externe Schnittstelle der Karten ist PCI Express 4.0, und jede Schnittstellenkarte trägt ein Paar DIPs. Auf jeder Seite jeder Kachelreihe sind 5 DIPs installiert, was eine Geschwindigkeit von bis zu 4,5 TB / s von HBM-Stacks zu Kacheln ergibt.
In Fällen, in denen der Kachel-zu-Kachel-Zugriff im gesamten System zu viele Hops erfordert (bis zu 30 bei Edge-to-Edge-Zugriff), kann das System DIPs verwenden, die extern über ein 400-GbE-Fat-Tree-Netzwerk verbunden sind, wodurch die Anzahl der Sprünge auf maximal vier. Der Durchsatz leidet in diesem Fall, aber die Latenz gewinnt, was in einigen Szenarien wichtiger ist.
In der Basisversion produziert der Supercomputer Dojo V1 1 Eflops im BF16/CFP8-Modus und kann Modelle bis zu 1,3 TB direkt in SRAM laden, weitere 13 TB an Daten können in DIP-HBM-Baugruppen gespeichert werden. Es sei darauf hingewiesen, dass der SRAM-Raum im gesamten Dojo-System eine einzige flache Adressierung verwendet. Die Vollversion von Dojo wird eine Leistung von bis zu 20 EFlops haben.
Wie viel Aufwand das Unternehmen braucht, um ein solches Monster auf den Markt zu bringen und vor allem mit funktionierender und nützlicher Software zu versorgen, ist unbekannt - aber offensichtlich eine Menge. Es ist bekannt, dass das System mit PyTorch kompatibel ist. Tesla bekommt derzeit fertige D1-Chips von TSMC. Mittlerweile begnügt sich das Unternehmen mit dem weltweit größten installierten NVIDIA-KI-Supercomputer.
2022-09-06 07:41:21
Autor: Vitalii Babkin