テスラは、同社の研究所で作成された独自の D1 プロセッサをすでに発表しており、これが Dojo AI スーパーコンピューターの基礎となります。 AIドライバーの仮想トレーニング場を作成し、道路上の実際の状況を詳細に再現するには、このようなシステムが必要です.当然のことながら、このようなシミュレーターには膨大な計算能力が必要です。私たちの世界では、交通状況は非常に複雑で変化しやすく、多くの要因や変数が含まれています。
最近まで、Dojo と D1 についてはあまり知られていませんでしたが、Hot Chips 34 カンファレンスでは、このテスラ ソリューションのアーキテクチャ、設計、および機能について多くの興味深いことが明らかになりました。このプレゼンテーションは、AMD で 17 年間サーバー プロセッサの設計に携わっていた Emil Talpes が司会を務めました。彼は、他の多くの著名な開発者と同様に、現在テスラで同社のハードウェアの作成と改善に取り組んでいます。
D1の主なアイデアはスケーラビリティであったため、新しいチップの開発の開始時に、作成者はコヒーレンス、仮想メモリなどの従来の概念の役割を積極的に再考しました. - 本当に大規模なコンピューティング システムを構築する場合、すべてのメカニズムが最適な方法でスケーリングされるわけではありません。代わりに、SRAM に基づく分散ストレージ ネットワークが優先され、分散コンピューティング システムの既存の実装よりも桁違いに優れた相互接続が作成されました。
Tesla プロセッサの基礎は、RISC-V セットからのいくつかの命令に基づく整数計算コアでしたが、会社が使用する機械学習コアの要件に合わせて最適化された多数の独自の命令によって補完されました。開発者によると、ベクトル演算ブロックはほぼゼロから作成されました。
Dojo の命令セットには、スカラー、マトリックス、SIMD 命令のほか、データをローカル メモリからリモート メモリに移動するための特定のプリミティブ、およびバリアを備えたセマフォが含まれています。セマフォは、システム全体でメモリ作業を調整するために必要です。機械学習の具体的な手順については、ハードウェアの Dojo に実装されています。
シリーズで最初に誕生した D1 チップは、それ自体がアクセラレータではなく、特定のアクセラレータを必要としない高性能の汎用プロセッサであると同社は考えています。各 Dojo 計算ユニットは、ローカル・メモリーと I/O インターフェースを備えた単一の D1 コアによって表されます。これは 64 ビットのスーパースカラー カーネルです。
さらに、カーネルはマルチスレッド (SMT4) をサポートしています。これは、(異なるタスクを互いに分離するのではなく) クロックごとのパフォーマンスを向上させるように設計されているため、この SMT 実装は仮想メモリをサポートしておらず、保護メカニズムの機能はかなり制限されています。専用のソフトウェア・スタックと専用ソフトウェアが、Dojo リソースの管理を担当します。
64 ビット カーネルには 32 バイトのフェッチ ウィンドウがあり、デコーダーの幅に対応する最大 8 つの命令を含めることができます。次に、1 サイクルあたり 2 つのスレッドを処理できます。結果はスケジューラに送られ、スケジューラはそれを整数計算ユニット (2 つの ALU) またはベクトルユニット (64 バイト幅の SIMD + 8×8×4 行列乗算) に送信します。
各 D1 コアには 1.25 MB の SRAM があります。このメモリはキャッシュではありませんが、400 GB / sの速度でデータをロードし、270 GB / sの速度で保存できます。また、すでに述べたように、チップには特別な命令が実装されているため、作業が可能です他の Dojo コアのデータと。このため、SRAM ブロックには独自のメカニズムがあるため、リモート メモリの操作に追加の操作は必要ありません。
サポートされるデータ形式に関しては、スカラー ブロックは 8 ~ 64 ビットの整数形式をサポートし、ベクトル ブロックと行列ブロックは混合精度計算を含む幅広い浮動小数点形式をサポートします: FP32、BF16、CFP16、および CFP8。 D1 の開発者は、構成可能な 8 ビットおよび 16 ビットのデータ表現のセット全体を使用するようになりました。Dojo コンパイラーは仮数と指数の値を動的に変更できるため、システムは最大 16 の異なるベクトル形式を使用できます。 、変わらない限り。
すでに述べたように、D1 トポロジーは、12 個のコアごとに論理ブロックに結合されるメッシュ構造を使用します。 D1 チップ全体は 18×20 コアのアレイですが、チップ上に存在する 360 個のコアのうち 354 個しか使用できません。 645mm2 のダイ自体は、TSMC の施設で 7nm プロセス技術を使用して製造されています。クロック周波数は 2 GHz、SRAM の総量は 440 MB です。
D1 プロセッサは、BF16 / CFP8 モードで 362 Tflops を開発し、FP32 モードでは、この数値は 22 Tflops に低下します。 FP64 モードは D1 ベクトル ブロックではサポートされていないため、このプロセッサは多くの従来の HPC ワークロードには適していません。しかし、Tesla は内部使用のために D1 を構築したため、互換性についてはあまり気にしません。ただし、新しい世代の D2 または D3 では、会社の目標に適合する場合、そのようなサポートが表示される可能性があります。
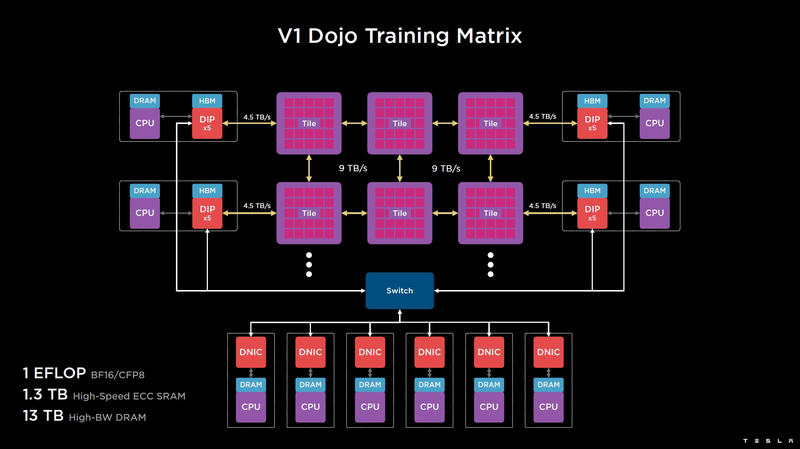
各 D1 ダイには 576 ビットの外部 SerDes インターフェイスがあり、4 つの側面すべてで合計 8 TB/秒のパフォーマンスを発揮するため、D1 を接続する際にボトルネックになることはありません。このインターフェースは、クリスタルを単一の 5x5 マトリックスに結合します。このような 25 個の D1 クリスタルのマトリックスは Dojo トレーニング タイルと呼ばれます。
このタイルは完全な熱電気機械モジュールとして設計されており、帯域幅が片面あたり 4.5 TB/s の外部インターフェイス、合計 11 GB の SRAM、および独自の 15 kW 電源システムを備えています。 1 つの Dojo タイルの処理能力は、BF16/CFP8 形式で 9 PFlops です。このレベルの消費電力では、Dojo は液体冷却しかできません。
タイルを組み合わせてさらに生産的なマトリックスにすることもできますが、Tesla スーパーコンピューターが物理的にどのように構成されているかは完全には明らかではありません。外の世界と通信するために、DIP ブロック (Dojo Interface Processors) が使用されます。これらは、タイルがホスト システムと通信するためのインターフェイス プロセッサであり、制御機能、データ配列のストレージなどが割り当てられます。各 DIP は IO 機能を実行するだけでなく、32 GB の HBM メモリ (指定なし、HBM2e または HBM3) も含みます。
DIPは、Teslaによって開発され、900 GB /秒のスループットを提供するトランスポートプロトコル全体(Tesla Transport Protocol、TTP)を使用し、イーサネット経由で50 GB /秒を提供します。カードの外部インターフェイスは PCI Express 4.0 で、各インターフェイス カードには 1 組の DIP があります。タイルの各列の両側に 5 つの DIP が取り付けられており、HBM スタックからタイルまで最大 4.5 TB/秒の速度が得られます。
システム全体のタイルからタイルへのアクセスに必要なホップ数が多すぎる場合 (エッジからエッジへのアクセスの場合は最大 30)、システムは 400GbE ファット ツリー ネットワークによって外部に接続された DIP を使用できます。ホップ数を最大 4 にします。この場合、スループットは低下しますが、一部のシナリオではより重要な遅延が優先されます。
基本バージョンでは、Dojo V1 スーパーコンピューターは BF16 / CFP8 モードで 1 Eflops を生成し、最大 1.3 TB のモデルを SRAM に直接ロードでき、さらに 13 TB のデータを DIP HBM アセンブリに保存できます。 Dojo システム全体の SRAM スペースは、単一のフラットなアドレス指定を使用することに注意してください。 Dojo のフル スケール バージョンでは、最大 20 eflops のパフォーマンスが得られます。
同社がそのようなモンスターを立ち上げ、最も重要なことに、機能する有用なソフトウェアを提供するためにどれだけの労力を必要とするかは不明ですが、明らかに多くの労力が必要です.このシステムは、PyTorch と互換性があることが知られています。テスラは現在、TSMC から既製の D1 チップを入手しています。その間、同社は世界最大のインストール済み NVIDIA AI スーパーコンピューターでやりくりしています。
2022-09-06 07:41:21
著者: Vitalii Babkin