Hot Chips 34 カンファレンスで、NVIDIA は、Hopper アーキテクチャに基づく今後の H100 アクセラレータに関する新しい詳細を共有しました。 GH100 チップには 800 億個のトランジスタが含まれており、NVIDIA と共同で作成された、NVIDIA のニーズに合わせて特別に最適化された TSMC N4 プロセス テクノロジを使用して製造されています。このアクセラレータは、世界で初めて HBM3 メモリを採用します。
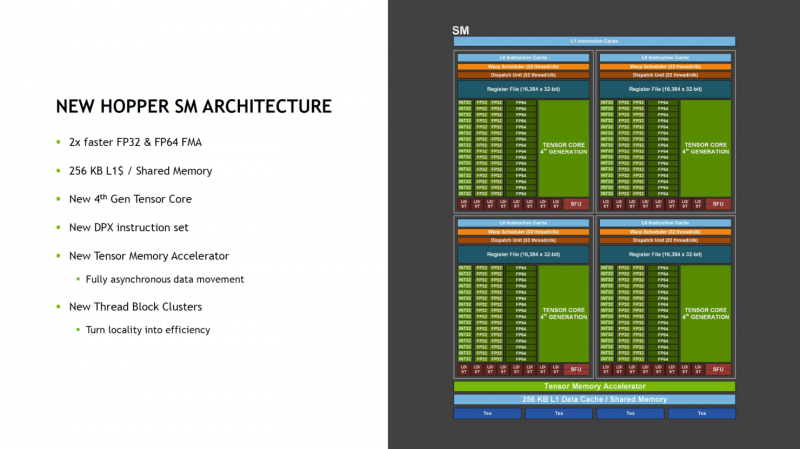
このチップには一度に 144 個のストリーミング マルチプロセッサ (SM) があり、物理的に 128 個のブロックが存在する A100 よりも幾分多くなっています. アクティブなブロックは 132 個しかありませんが、NVIDIA は、前の世代と同じ頻度で。これは、FP32 および FP64 FMA モジュールの両方に適用されます。さらに、高い計算精度を必要としない機械学習シナリオでますます一般的になっている FP8 形式がサポートされています。
このモードでは、NVIDIA は、最も一般的な FP8 形式である E5M2 と E4M3 の両方をサポートしていました。つまり、指数はそれぞれ 5 ビットまたは 4 ビット、仮数は 2 ビットまたは 3 ビットの形式で表現されます。各 FP8 テンソル ブロックは、FP8 形式の 2 つの行列の乗算を提供し、結果のさらなる蓄積と変換を行いますが、ここで最も重要なことは、新しい Transformer Engine ブロックの存在により、最適な FP8 バリアントの選択が次のようになることです。自動的に実行されます。 NVIDIA によると、FP8 対応のテンソル プロセッサの高度なアーキテクチャは、FP16 に匹敵する精度を提供しますが、パフォーマンスは 2 倍、メモリ フットプリントは半分です。
合計で、各 SM ブロックには 128 個の FP32 モジュール、64 個の INT32 および FP64 モジュール、4 個のテンソル コア、およびテンソル メモリ アクセラレータと合計 256 KB の L1 キャッシュがあります。 L2 キャッシュの容量は 50 MB にもなります。現在の実装では、18432 の可能な CUDA コアのうち 16896 の CUDA コアと、576 の 528 のテンソル コアが利用可能であり、NVIDIA によると、新しい第 4 世代のテンソル コンピューティング モジュールも 2 倍の速度になっています。新しい DPX 命令セットのサポート、データ移動時の非同期のサポートなどを実装しました。
MIG (Multi-instance GPU) テクノロジは第 2 世代に成長しました。現在、そのような仮想アクセラレータはそれぞれ、3 倍のコンピューティング能力と 2 倍のメモリ帯域幅になっています。後者は、HBM3 を使用して実現されます。このバージョンでは、それぞれ 16 GB の容量を持つ HBM3 アセンブリ (5120 ビット バス) が使用されます。 5 つのアセンブリは、3 TB/秒のメモリ帯域幅で 80 GB のローカル メモリを提供します。組立シートは 6 箇所ありますが、1 箇所はチップの高さを揃えるためだけに使用します。
同時に、GH100 の仮想化は可能な限り完全です。各 vGPU のメモリ領域の分離を提供する特殊なファイアウォール ブロックや整合性をチェックするためのブロックなど、ハードウェア レベルでの信頼できるコンピューティングのサポートが提供されます。データの機密性を維持します。前に、新世代の NVLink 4 インターコネクトのサポートについて説明しました。このインターフェイスは、複数のチップとアクセラレータを組み合わせて最大 900 GB/秒を提供しますが、最も重要なのは、柔軟なスケーリング オプションを提供することです。
GH100 には、もう 1 つの重要な技術革新、つまり変更されたメモリ階層があります。そのため、SM-to-SM 相互接続により、4 つの各 SM が相互に直接通信できるようになり、不要なトランザクションで共通バスに負荷がかかることはありません。これにより、仮想化の効率が向上し、アクセラレータの「メイン パス」の帯域幅が大幅に節約されます。非同期実行とデータ交換のサポートと合わせて、これによりレイテンシが短縮され、場合によっては最大 7 倍になります。
NVIDIA が GH100 の可能性を完全に認識しているかどうかは現時点では不明ですが、これにより、目新しさのすでに深刻な可能性が高まる可能性があります。ただし、そのような電力は無駄ではありません。短縮版であっても、最適化された技術プロセスを使用していても、SXM5 形式 (PG520 ボード) の GH100 ベースのアクセラレータの TDP は 700 W です。
間違いなく、GH100 は GA100 に比べて大きな前進ですが、競争は深刻です。たとえば、新製品は Intel Ponte Vecchio ベースのアクセラレータと戦わなければならず、1:1 の FP32 / FP64 比を約束します。 NVIDIA ソリューションの 2:1 に対して。興味深い事実: 新しいチップの単一の GPC クラスターは、わずか 10 年前にリリースされた GK110 Kepler チップ全体よりも 20% 強力です。
2022-08-28 16:22:56
著者: Vitalii Babkin