Auf der Hot Chips 34-Konferenz teilte NVIDIA neue Details über die kommenden H100-Beschleuniger auf Basis der Hopper-Architektur mit. Der GH100-Chip enthält 80 Milliarden Transistoren und wird mit der speziell für die Bedürfnisse von NVIDIA optimierten TSMC N4-Prozesstechnologie hergestellt, die in Zusammenarbeit mit NVIDIA entwickelt wurde. Der Beschleuniger wird der erste weltweit sein, der HBM3-Speicher erhält.
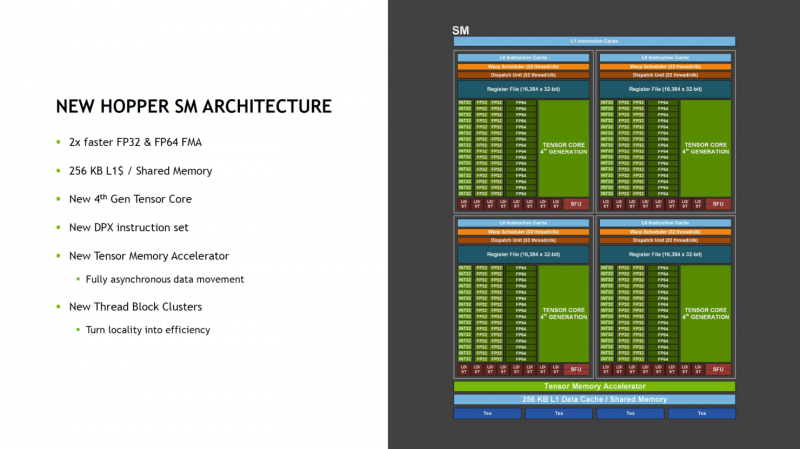
Der Chip verfügt über 144 Streaming-Multiprozessoren (SMs) auf einmal, das ist etwas mehr als beim A100, wo es physisch 128 solcher Blöcke gibt.Es gibt nur 132 aktive Blöcke, aber NVIDIA behauptet im Vergleich zu den neuen SMs die doppelte Leistung vorherige Generation mit gleicher Frequenz . Dies gilt sowohl für FP32- als auch für FP64-FMA-Module. Darüber hinaus gibt es Unterstützung für das FP8-Format, das in maschinellen Lernszenarien immer häufiger verwendet wird, die keine hohe Rechengenauigkeit erfordern.
In diesem Modus unterstützte NVIDIA die beiden gängigsten FP8-Formate: E5M2 und E4M3, also die Darstellung einer Zahl in Form von 5 bzw. 4 Bit für den Exponenten bzw. 2 bzw. 3 Bit für die Mantisse. Jeder FP8-Tensorblock bietet die Multiplikation zweier Matrizen im FP8-Format mit weiterer Akkumulation und Transformation des Ergebnisses, aber das Wichtigste hier ist, dass aufgrund des Vorhandenseins des neuen Transformer-Engine-Blocks die Auswahl der am besten geeigneten FP8-Variante ist automatisch durchgeführt. Laut NVIDIA bietet die fortschrittliche Architektur von FP8-fähigen Tensor-Prozessoren eine vergleichbare Präzision wie FP16, jedoch bei doppelter Leistung und halb so großem Speicherbedarf.
Insgesamt verfügt jeder SM-Block über 128 FP32-Module, 64 INT32- und FP64-Module und 4 Tensorkerne sowie einen Tensor-Speicherbeschleuniger und einen L1-Cache von insgesamt 256 KB. Das Volumen des L2-Cache beträgt bis zu 50 MB. In der aktuellen Implementierung stehen 16896 CUDA-Kerne von 18432 möglichen und 528 Tensor-Kerne von 576 zur Verfügung.Auch die neuen Tensor-Computing-Module der vierten Generation sind laut NVIDIA doppelt so schnell geworden. Implementierte Unterstützung für einen neuen Satz von DPX-Anweisungen, Unterstützung für Asynchronität beim Verschieben von Daten usw.
Die MIG-Technologie (Multi-Instanz-GPU) ist auf die zweite Generation angewachsen. Jetzt hat jeder dieser virtuellen Beschleuniger dreimal mehr Rechenleistung und doppelt so viel Speicherbandbreite. Letzteres wird durch den Einsatz von HBM3 erreicht. In dieser Version werden HBM3-Baugruppen mit einer Kapazität von jeweils 16 GB (5120-Bit-Bus) verwendet. Fünf Baugruppen ergeben 80 GB lokalen Speicher mit einer Speicherbandbreite von 3 TB/s. Es gibt sechs Montagesitze, aber einer wird nur zum Nivellieren der Höhe des Chips verwendet.
Gleichzeitig ist die Virtualisierung des GH100 so vollständig wie möglich: Unterstützung für vertrauenswürdiges Computing auf Hardwareebene wird bereitgestellt, einschließlich spezialisierter Firewall-Blöcke, die eine Isolierung der Speicherbereiche jeder vGPU bieten, sowie Blöcke zur Überprüfung der Integrität und Wahrung des Datengeheimnisses. Wir haben bereits über die Unterstützung der neuen Generation der NVLink 4-Verbindung gesprochen - diese Schnittstelle bietet bis zu 900 GB / s für die Kombination mehrerer Chips und Beschleuniger, bietet aber vor allem flexible Skalierungsoptionen.
Die GH100 hat außerdem eine weitere wichtige Neuerung – eine modifizierte Speicherhierarchie. Somit ermöglicht die SM-zu-SM-Verbindung jeweils vier SMs, direkt miteinander zu kommunizieren und den gemeinsamen Bus nicht mit unnötigen Transaktionen zu belasten. Das erhöht die Effizienz bei der Virtualisierung und spart massiv Bandbreite der „Hauptpfade“ des Beschleunigers ein. Zusammen mit der Unterstützung für asynchrone Ausführung und Datenaustausch wird dies die Latenz reduzieren, in einigen Fällen um das bis zu siebenfache.
Ob NVIDIA das volle Potenzial der GH100 ausschöpft, ist derzeit unklar, aber dies könnte das ohnehin schon ernsthafte Potenzial der Neuheit erhöhen. Solche Power gibt es aber nicht umsonst: Selbst in abgespeckter Version und trotz Einsatz eines optimierten technischen Verfahrens wird ein Beschleuniger auf Basis des GH100 im SXM5-Format (PG520-Board) eine TDP von 700 W aufweisen.
Zweifellos ist der GH100 im Vergleich zum GA100 ein großer Schritt nach vorne, aber die Konkurrenz wird ernst sein: Beispielsweise muss das neue Produkt mit Beschleunigern auf Basis von Intel Ponte Vecchio kämpfen, und sie versprechen ein 1:1-Verhältnis von FP32 / FP64 gegen 2:1 für die NVIDIA-Lösung. Eine interessante Tatsache: Der einzelne GPC-Cluster des neuen Chips ist 20 % leistungsstärker als der gesamte GK110-Kepler-Chip, der vor nur 10 Jahren veröffentlicht wurde.
2022-08-28 16:22:56
Autor: Vitalii Babkin