Lors de la conférence Hot Chips 34, NVIDIA a partagé de nouveaux détails sur les prochains accélérateurs H100 basés sur l'architecture Hopper. La puce GH100 contient 80 milliards de transistors et est fabriquée à l'aide de la technologie de processus TSMC N4, spécialement optimisée pour les besoins de NVIDIA, créée en collaboration avec NVIDIA. L'accélérateur sera le premier au monde à recevoir de la mémoire HBM3.
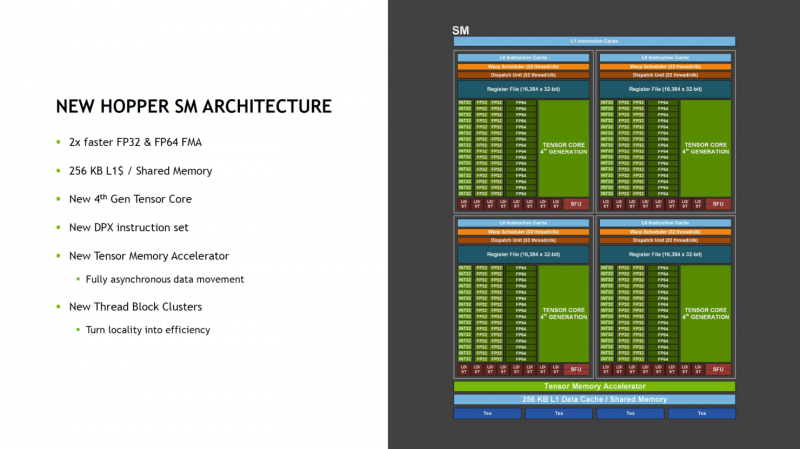
La puce dispose de 144 multiprocesseurs de streaming (SM) à la fois, ce qui est un peu plus que dans l'A100, où il y en a physiquement 128. Il n'y a que 132 blocs actifs, mais NVIDIA revendique deux fois les performances des nouveaux SM par rapport au génération précédente à fréquence égale. Ceci s'applique aux modules FMA FP32 et FP64. De plus, le format FP8 est pris en charge, ce qui est de plus en plus courant dans les scénarios d'apprentissage automatique qui ne nécessitent pas une grande précision de calcul.
Dans ce mode, NVIDIA supportait les deux formats FP8 les plus courants : E5M2 et E4M3, c'est-à-dire la représentation d'un nombre sous la forme de 5 ou 4 bits pour l'exposant et de 2 ou 3 bits pour la mantisse, respectivement. Chaque bloc tenseur FP8 fournit la multiplication de deux matrices au format FP8 avec une accumulation et une transformation supplémentaires du résultat, mais le plus important ici est qu'en raison de la présence du nouveau bloc Transformer Engine, la sélection de la variante FP8 la plus appropriée est effectué automatiquement. Selon NVIDIA, l'architecture avancée des processeurs tenseurs compatibles FP8 offre une précision comparable à celle du FP16, mais à deux fois les performances et la moitié de l'empreinte mémoire.
Au total, chaque bloc SM comporte 128 modules FP32, 64 modules INT32 et FP64 et 4 cœurs tensoriels, ainsi qu'un accélérateur de mémoire tensorielle et un cache L1 total de 256 Ko. Le volume du cache L2 atteint 50 Mo. Dans l'implémentation actuelle, 16896 cœurs CUDA sur 18432 possibles et 528 cœurs tensoriels sur 576 sont disponibles.Selon NVIDIA, les nouveaux modules de calcul tensoriels de quatrième génération sont également devenus deux fois plus rapides. Prise en charge implémentée d'un nouveau jeu d'instructions DPX, prise en charge de l'asynchronisme lors du déplacement de données, etc.
La technologie MIG (Multi-instance GPU) est passée à la deuxième génération. Désormais, chacun de ces accélérateurs virtuels est devenu trois fois plus puissant en termes de puissance de calcul et deux fois plus de bande passante mémoire. Ce dernier est réalisé grâce à l'utilisation de HBM3. Dans cette version, des assemblages HBM3 d'une capacité de 16 Go chacun (bus 5120 bits) sont utilisés. Cinq assemblages donnent 80 Go de mémoire locale avec une bande passante mémoire de 3 To/s. Il y a six sièges d'assemblage, mais un n'est utilisé que pour niveler la hauteur de la puce.
Dans le même temps, la virtualisation du GH100 est aussi complète que possible : une prise en charge de l'informatique de confiance au niveau matériel est fournie, y compris des blocs de pare-feu spécialisés qui assurent l'isolation des régions de mémoire de chaque vGPU, ainsi que des blocs pour vérifier l'intégrité. et le maintien de la confidentialité des données. Nous avons parlé plus tôt de la prise en charge de la nouvelle génération d'interconnexion NVLink 4 - cette interface fournit jusqu'à 900 Go / s pour combiner plusieurs puces et accélérateurs, mais, surtout, offre des options de mise à l'échelle flexibles.
Le GH100 a également une autre innovation importante - une hiérarchie de mémoire modifiée. Ainsi, l'interconnexion SM à SM permet à chacun des quatre SM de communiquer directement entre eux et de ne pas charger le bus commun avec des transactions inutiles. Cela augmente l'efficacité de la virtualisation et économise sérieusement la bande passante des "chemins principaux" de l'accélérateur. Avec la prise en charge de l'exécution asynchrone et de l'échange de données, cela réduira la latence, dans certains cas jusqu'à sept fois.
On ne sait pas encore si NVIDIA réalise le plein potentiel du GH100, mais cela pourrait augmenter le potentiel déjà sérieux de la nouveauté. Cependant, une telle puissance n'est pas donnée en vain : même dans une version tronquée et même malgré l'utilisation d'un procédé technique optimisé, un accélérateur basé sur le GH100 au format SXM5 (carte PG520) aura un TDP de 700 W.
Sans aucun doute, le GH100 est un énorme pas en avant par rapport au GA100, mais la concurrence sera sérieuse : par exemple, le nouveau produit devra se battre avec des accélérateurs à base d'Intel Ponte Vecchio, et ils promettent un rapport 1:1 FP32 / FP64 contre 2:1 pour la solution NVIDIA. Fait intéressant : le cluster GPC unique de la nouvelle puce est 20 % plus puissant que l'ensemble de la puce GK110 Kepler sortie il y a à peine 10 ans.
2022-08-28 16:22:56
Auteur: Vitalii Babkin