Untether AI hat die nächste Generation der KI-Architektur speedAI (Codename „Boqueria“) angekündigt, die sich auf Inferenzlasten konzentriert. Mit einer Energieeffizienz von 30 Tflops/W und einer Leistung von bis zu 2 Pflops pro Chip setzt speedAI einen neuen Standard für Energieeffizienz und Rechendichte, so das Unternehmen.
Da At-Memory-Computing bei einigen Aufgaben wesentlich energieeffizienter ist als herkömmliche Architekturen, kann es bei gleicher Energiemenge eine höhere Leistung erbringen. Untether AI, die erste Generation von runAI-Geräten im Jahr 2020, erreicht eine Energieeffizienz von 8 Tflops/W für INT8-Computing. Die neue speedAI-Architektur liefert bereits 30 TFlops/W.
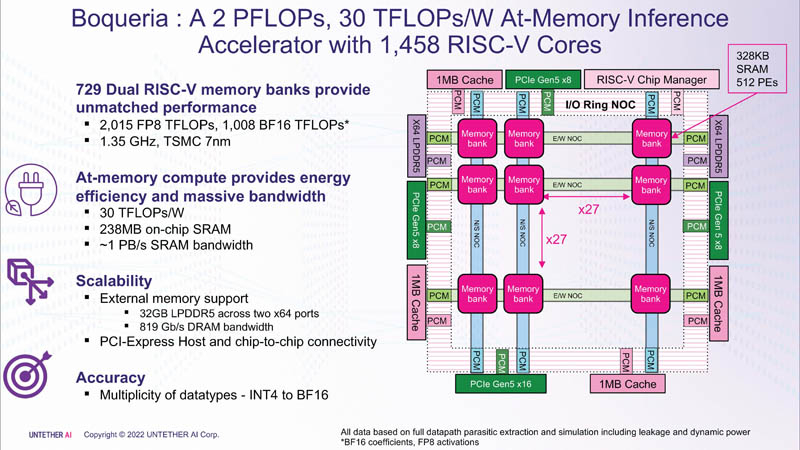
Dies wurde dank der Architektur der zweiten Generation, der Verwendung von mehr als 1400 optimierten 7-nm-RISC-V-Kernen (1,35 GHz) mit benutzerdefinierten Anweisungen, einer energieeffizienten Datenflusskontrolle und der Einführung der FP8-Unterstützung erreicht. Zusammen ermöglichte dies eine Vervierfachung der Effizienz von speedAI im Vergleich zu runAI. Die Neuheit lässt sich flexibel an verschiedene Architekturen neuronaler Netze anpassen. Konzeptionell ähnelt speedAI einem anderen RISC-V-Chip mit Tausend Kernen – Esperanto ET-SoC-1.
Das erste Mitglied der speedAI-Familie, speedAI240, bietet 2 Pflops für FP8-Berechnungen oder 1 Pflops für BF16-Operationen. Dies führt zu einer branchenführenden Effizienz, wie z. B. dem Leistungsanspruch von BERT von 750 Anfragen pro Sekunde pro Watt (qps/w), was nach Angaben des Unternehmens 15-mal schneller ist als die heutigen GPUs. Durch die enge Verzahnung von Rechenelementen und Speicher konnte eine Leistungssteigerung erreicht werden.
Für jeden 328-KB-SRAM-Block gibt es 512 Recheneinheiten, die die Formate INT4, INT8, FP8 und BF16 unterstützen. Jede Recheneinheit verfügt über zwei benutzerdefinierte 32-Bit-RISC-V-Kerne (RV32EMC) mit Unterstützung für vier Threads und 64 SIMDs. Es gibt insgesamt 729 Blöcke, also trägt der Chip insgesamt 238 MB SRAM und 1458 Kerne. Die Blöcke sind durch ein Mesh-Netzwerk miteinander verbunden, an das auch ein Ring-IO-Bus angeschlossen ist, der vier 1-MB-Shared-Cache-Blöcke, zwei LPDRR5-Controller (64 Bit) und PCIe 5.0-Ports trägt: einen x16 für die Verbindung zum Host und drei x8 zum Kombinieren von Chips.
Der Gesamtdurchsatz von SRAM beträgt etwa 1 PB/s, Mesh-Netzwerke 1,5 bis 1,9 TB/s, IO-Busse 141 GB/s in beide Richtungen und 32 GB DRAM knapp über 100 GB/s. Über PCIe-Schnittstellen können Sie bis zu drei Beschleuniger mit jeweils sechs speedAI240-Chips kombinieren. speedAI-Lösungen werden sowohl in Form einzelner Chips als auch als Teil fertiger PCIe-Karten und M.2-Module angeboten. Erste Auslieferungen an ausgewählte Kunden sollen im ersten Halbjahr 2023 beginnen.
2022-08-25 04:02:28
Autor: Vitalii Babkin