Untether AI a annoncé l'architecture d'IA de nouvelle génération speedAI (nom de code "Boqueria"), axée sur les charges d'inférence. Avec une efficacité énergétique de 30 Tflops/W et des performances allant jusqu'à 2 Pflops par puce, speedAI établit une nouvelle norme en matière d'efficacité énergétique et de densité de calcul, selon la société.
Étant donné que l'informatique en mémoire est beaucoup plus économe en énergie que les architectures traditionnelles dans certaines tâches, elle peut fournir des performances supérieures pour la même quantité d'énergie. La première génération d'appareils runAI en 2020, Untether AI atteint une efficacité énergétique de 8 Tflops/W pour le calcul INT8. La nouvelle architecture speedAI fournit déjà 30 TFlops/W.
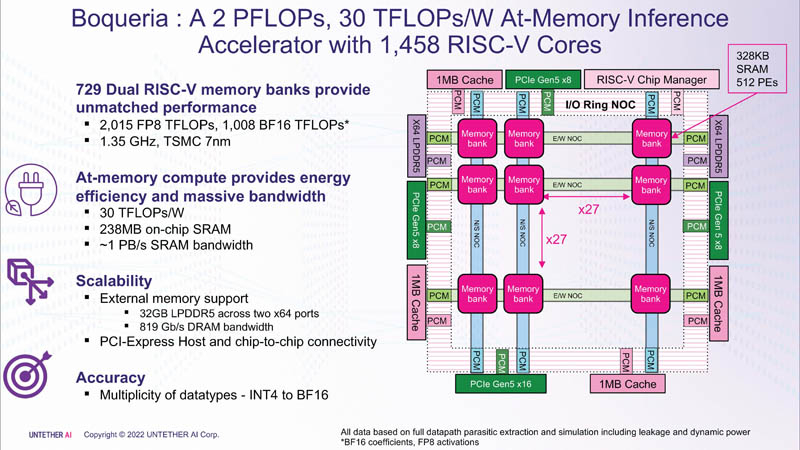
Ceci a été réalisé grâce à l'architecture de deuxième génération, à l'utilisation de plus de 1400 cœurs RISC-V optimisés de 7 nm (1,35 GHz) avec des instructions personnalisées, un contrôle de flux de données économe en énergie et l'introduction du support FP8. Ensemble, cela a permis de quadrupler l'efficacité de speedAI par rapport à runAI. La nouveauté peut être adaptée de manière flexible à diverses architectures de réseaux neuronaux. Conceptuellement, speedAI ressemble à une autre puce RISC-V à mille cœurs - Esperanto ET-SoC-1.
Le premier membre de la famille speedAI, speedAI240, fournit 2 Pflops pour les calculs FP8 ou 1 Pflops pour les opérations BF16. Cela se traduit par une efficacité à la pointe de l'industrie, telle que la performance annoncée par BERT de 750 requêtes par seconde par watt (qps/w), qui, selon la société, est 15 fois plus rapide que les GPU actuels. Il a été possible d'obtenir une augmentation des performances grâce à l'intégration étroite des éléments informatiques et de la mémoire.
Pour chaque bloc SRAM de 328 Ko, 512 unités de calcul prennent en charge les formats INT4, INT8, FP8 et BF16. Chaque unité de calcul possède deux cœurs RISC-V personnalisés 32 bits (RV32EMC) avec prise en charge de quatre threads et 64 SIMD. Il y a 729 blocs au total, donc au total, la puce contient 238 Mo de SRAM et 1458 cœurs. Les blocs sont connectés les uns aux autres par un réseau maillé, auquel est également connecté un bus d'E/S en anneau, transportant quatre blocs de cache partagé de 1 Mo, deux contrôleurs LPDRR5 (64 bits) et des ports PCIe 5.0 : un x16 pour la connexion à l'hôte et trois x8 pour combiner les puces.
Le débit total de la SRAM est d'environ 1 Po/s, les réseaux maillés sont de 1,5 à 1,9 To/s, les bus d'E/S sont de 141 Go/s dans les deux sens et la DRAM de 32 Go représente un peu plus de 100 Go/s. Les interfaces PCIe vous permettent de combiner jusqu'à trois accélérateurs, avec six puces speedAI240 chacun. Les solutions speedAI seront proposées à la fois sous la forme de puces individuelles et dans le cadre de cartes PCIe et de modules M.2 prêts à l'emploi. Les premières livraisons aux clients sélectionnés devraient commencer au premier semestre 2023.
2022-08-25 04:02:28
Auteur: Vitalii Babkin