Untether AI は、推論負荷に焦点を当てた次世代 AI アーキテクチャ speedAI (コードネーム「Boqueria」) を発表しました。 30 Tflops/W のエネルギー効率と、チップあたり最大 2 Pflops のパフォーマンスを備えた speedAI は、電力効率と計算密度の新しい基準を設定します。
アットメモリ コンピューティングは、一部のタスクにおいて従来のアーキテクチャよりもはるかにエネルギー効率が高いため、同じ量のエネルギーでより高いパフォーマンスを提供できます。 2020 年の第 1 世代の runAI デバイスである Untether AI は、INT8 コンピューティングで 8 Tflops/W のエネルギー効率を達成します。新しい speedAI アーキテクチャは、すでに 30 TFlops/W を提供しています。
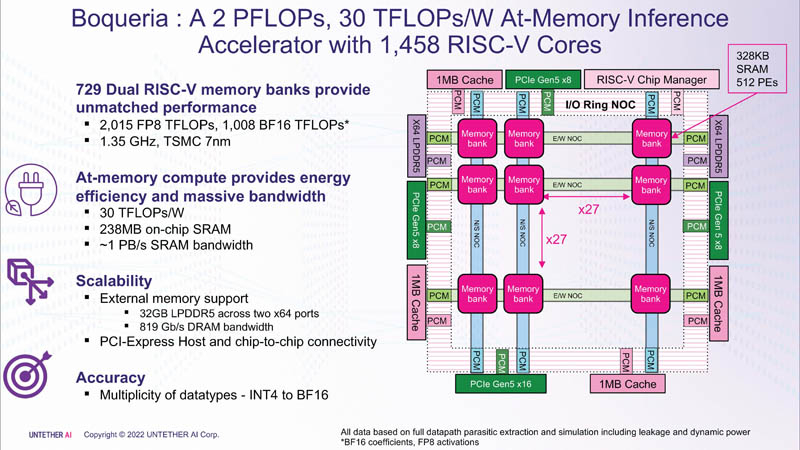
これは、第 2 世代アーキテクチャ、カスタム命令を備えた 1400 以上の最適化された 7nm RISC-V コア (1.35 GHz) の使用、エネルギー効率の高いデータ フロー制御、および FP8 サポートの導入により達成されました。これにより、runAI と比較して speedAI の効率を 4 倍にすることが可能になりました。この新規性は、ニューラル ネットワークのさまざまなアーキテクチャに柔軟に適応できます。概念的には、speedAI は別の 1000 コア RISC-V チップである Esperanto ET-SoC-1 に似ています。
speedAI ファミリの最初のメンバーである speedAI240 は、FP8 計算用に 2 Pflops、または BF16 操作用に 1 Pflops を提供します。これにより、現在の GPU よりも 15 倍高速であると BERT が主張する 1 秒あたり 1 ワットあたり 750 リクエスト (qps/w) という BERT のパフォーマンス主張など、業界をリードする効率が実現します。計算要素とメモリの緊密な統合により、パフォーマンスの向上を達成することができました。
328 KB の SRAM ブロックごとに、INT4、INT8、FP8、および BF16 フォーマットをサポートする 512 個の計算ユニットがあります。各計算ユニットには、4 つのスレッドと 64 の SIMD をサポートする 2 つの 32 ビット (RV32EMC) カスタム RISC-V コアがあります。合計で 729 個のブロックがあるため、合計でチップには 238 MB の SRAM と 1458 個のコアが搭載されています。ブロックはメッシュ ネットワークによって相互に接続され、リング IO バスも接続され、4 つの 1 MB 共有キャッシュ ブロック、2 つの LPDRR5 コントローラー (64 ビット)、および PCIe 5.0 ポート (ホストに接続するための 1 つの x16) を搭載しています。と 3 つの x8 チップを組み合わせます。
SRAM の合計スループットは約 1 PB/秒、メッシュ ネットワークは 1.5 ~ 1.9 TB/秒、IO バスは双方向で 141 GB/秒、32 GB DRAM は 100 GB/秒をわずかに上回ります。 PCIe インターフェイスを使用すると、それぞれ 6 つの speedAI240 チップを使用して、最大 3 つのアクセラレータを組み合わせることができます。 speedAI ソリューションは、個々のチップの形でも、既製の PCIe カードと M.2 モジュールの一部としても提供されます。一部の顧客への最初の配送は、2023 年前半に開始される予定です。
2022-08-25 04:02:28
著者: Vitalii Babkin