Auf der GTC 2022 in diesem Frühjahr hat sich NVIDIA erstmals als Hersteller leistungsstarker Serverprozessoren angekündigt. Wir sprechen von Grace-Chips und Grace-Hopper-Hybridbaugruppen, die Arm v9-Kerne und -Beschleuniger basierend auf der Hopper-Architektur kombinieren, die in der ersten Hälfte des nächsten Jahres ausgeliefert werden sollen. Viele Entwickler von Supercomputern interessieren sich bereits für neue Produkte. Vor der Hot Chips 34-Konferenz enthüllte das Unternehmen eine Reihe von Details über die Chips.
Grace wird mit der TSMC 4N-Prozesstechnologie hergestellt – das ist eine speziell für NVIDIA-Lösungen optimierte Variante des N4, die Teil der 5-nm-Prozessserie des taiwanesischen Herstellers ist. Jeder Grace-Die enthält 72 ARM v9-Kerne, die skalierbare SVE2-Vektorerweiterungen und Virtualisierungserweiterungen unterstützen, die S-EL2 unterstützen. Wie bereits berichtet, hat NVIDIA den ARM Neoverse-Kern für die neue Plattform ausgewählt.
Der Grace-Prozessor entspricht auch einer Reihe anderer ARM-Spezifikationen, darunter RAS v1.1-konformer Generic Interrupt Controller (GIC) v4.1, System Memory Management Unit (SMMU) v3.1 und Memory Partitioning and Monitoring (MPAM). Grace hat zwei Basiskristalle, was insgesamt 144 Kerne ergibt – eine Rekordzahl sowohl in der Arm- als auch in der x86-Welt.
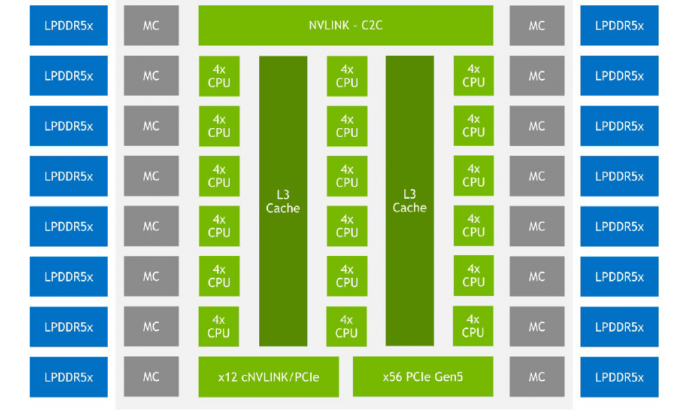
Grace-Inneneinheiten werden über das Scalable Coherency Fabric (SCF) verbunden, NVIDIAs Variante des CMN-700-Netzwerks, das in Arm Neoverse-Designs verwendet wird. Die Leistung dieser Verbindung beträgt 3,2 TB/s. Im Fall von Grace nimmt es 117 MB L3-Cache an und hält die Kohärenz innerhalb von vier Sockets aufrecht (durch die neue Version von NVLink).
Aber SCF unterstützt die Skalierung. In der Hardware ist es bisher auf zwei Grace-Blöcke beschränkt, und das sind bereits 144 Kerne und 234 MB L3-Cache. Kerne und Cache-Partitionen (SCC) werden über die interne Mesh-Factory SCF verteilt. Switches (CSNs) dienen als Schnittstellen zu Kernen, Cache-Partitionen und dem Rest des Systems. CSN-Blöcke kommunizieren direkt miteinander sowie mit LPDDR5X- und PCIe 5.0/cNVLink/NVLink C2C-Controllern.
Der Chip unterstützt PCI Express 5.0. Insgesamt unterstützt der Controller 68 Leitungen, von denen 12 auch im cNVLink-Modus (NVLink mit Kohärenz) arbeiten können. Eine x16-Schnittstelle kann in zwei x8-Schnittstellen aufgeteilt werden. Auch auf dem von NVIDIA bereitgestellten Diagramm können Sie bis zu 16 Zweikanal-LPDDR5x-Controller sehen. Deklarierte Speicherbandbreite auf dem Niveau von mehr als 1 TB / s für die Baugruppe (bis zu 546 GB / s pro CPU-Chip).
NVIDIA sieht eine neue Version von NVLink, NVLink-C2C, die siebenmal schneller als PCIe 5.0 ist und in der Lage ist, bidirektionale Datenübertragungsraten von bis zu 900 GB / s bereitzustellen, während sie fünfmal sparsamer ist. Der spezifische Verbrauch der Neuheit liegt bei 1,3 pJ/Bit und damit unter dem von AMD Infinity Fabric mit 1,5 pJ/Bit. Es gibt aber auch kostengünstigere Lösungen, zum Beispiel UCIe (~0,5 pJ/bit).
Mit NVLink-C2C können Sie einen einheitlichen „flachen“ Speicherpool mit einem gemeinsamen Adressraum für Grace Hopper implementieren. Innerhalb eines Knotens kann frei auf den Speicher von Nachbarn zugegriffen werden. Um jedoch mehrere Knoten zu kombinieren, benötigen Sie einen externen NVSwitch-Switch. Es wird 1 HE hoch sein und 128 NVLink 4-Ports mit bis zu 6,4 TB/s aggregierter Bandbreite im Duplex bereitstellen.
Dank einer optimierten Architektur und einer schnellen Verbindung verspricht Grace auch eine Rekordleistung. Selbst nach den von NVIDIA veröffentlichten vorläufigen Zahlen sprechen wir von 370 SPECrate2017_int_base-Punkten für einen einzelnen Grace-Die und 740 Punkten für eine 144-Core-Dual-Die-Assembly – und das unter Verwendung des üblichen GCC-Compilers ohne subtile Plattformoptimierungen. Letztere Zahl ist deutlich höher als die Ergebnisse des Alibaba T-Head Yitian 710 mit 128 Kernen, der ebenfalls die Arm v9-Architektur verwendet, und des AMD EPYC 7773X mit 64 Kernen.
2022-08-21 03:51:49
Autor: Vitalii Babkin