この春の GTC 2022 で、NVIDIA は、強力なサーバー プロセッサのメーカーであることを初めて発表しました。私たちは、Grace チップと Grace Hopper ハイブリッド アセンブリについて話しています。これは、Hopper アーキテクチャに基づいて Arm v9 コアとアクセラレータを組み合わせたもので、来年上半期に出荷が開始される予定です。スーパーコンピューターの開発者の多くは、すでに新製品に関心を持っています。 Hot Chips 34 カンファレンスに先立って、同社はチップに関する多くの詳細を明らかにしました。
Grace は TSMC 4N プロセス テクノロジを使用して製造されています。これは、台湾のメーカーの 5nm プロセス シリーズの一部である NVIDIA ソリューション用に特別に最適化された N4 の変形です。各 Grace ダイには、SVE2 スケーラブル ベクター拡張と S-EL2 をサポートする仮想化拡張をサポートする 72 個の Arm v9 コアが含まれています。以前に報告されたように、NVIDIA は新しいプラットフォームに Arm Neoverse コアを選択しました。
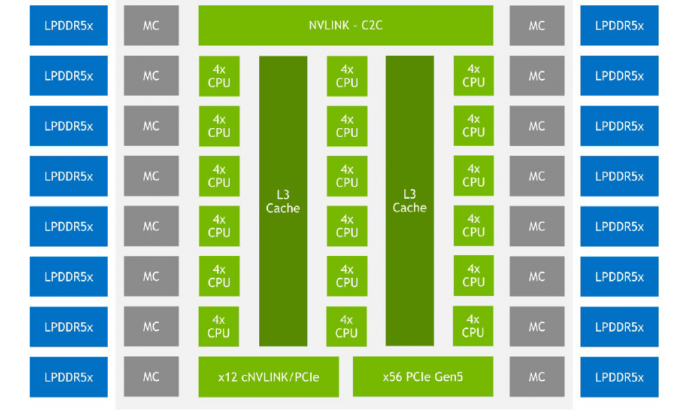
Grace プロセッサは、RAS v1.1 準拠の Generic Interrupt Controller (GIC) v4.1、System Memory Management Unit (SMMU) v3.1、Memory Partitioning and monitoring (MPAM) など、他の多くの Arm 仕様にも準拠しています。 Grace には 2 つのベース クリスタルがあり、合計 144 個のコアがあり、Arm と x86 の両方の世界で記録的な数です。
Grace 屋内ユニットは、ARM Neoverse 設計で使用される CMN-700 ネットワークの NVIDIA のバリエーションである Scalable Coherency Fabric (SCF) を介して接続されます。この相互接続のパフォーマンスは 3.2 TB/秒です。 Grace の場合、117 MB の L3 キャッシュを想定し、4 つのソケット内で一貫性を維持します (新しいバージョンの NVLink を介して)。
ただし、SCF はスケーリングをサポートしています。これまでのところ、ハードウェアでは 2 つの Grace ブロックに制限されており、これはすでに 144 コアと 234 MB の L3 キャッシュです。コアとキャッシュ パーティション (SCC) は、内部メッシュ ファクトリ SCF を介して分散されます。スイッチ (CSN) は、コア、キャッシュ パーティション、およびその他のシステムへのインターフェイスとして機能します。 CSN ブロックは、互いに直接通信するだけでなく、LPDDR5X および PCIe 5.0/cNVLink/NVLink C2C コントローラーとも通信します。
チップは PCI Express 5.0 をサポートします。合計で、コントローラーは 68 回線をサポートし、そのうち 12 回線は cNVLink モード (コヒーレンス付き NVLink) でも機能します。 x16 インターフェイスは、2 つの x8 インターフェイスに分岐できます。また、NVIDIA が提供する図では、最大 16 個のデュアルチャネル LPDDR5x コントローラーを確認できます。アセンブリ用に 1 TB/秒を超えるレベルで宣言されたメモリ帯域幅 (CPU チップあたり最大 546 GB/秒)。
NVIDIA は、PCIe 5.0 よりも 7 倍高速で、最大 900 GB/秒の双方向データ転送速度を提供できる一方で、5 倍経済的である NVLink の新しいバージョンである NVLink-C2C を見ています。ノベルティの比消費量は 1.3 pJ/ビットであり、AMD Infinity Fabric の 1.5 pJ/ビットよりも少ない。ただし、UCIe (~0.5 pJ/ビット) など、より経済的なソリューションもあります。
NVLink-C2C を使用すると、グレース ホッパーに共通のアドレス空間を持つ統合された「フラット」メモリ プールを実装できます。 1 つのノード内では、隣接するノードのメモリに自由にアクセスできます。ただし、複数のノードを組み合わせるには、外部 NVSwitch スイッチが必要になります。高さは 1U で、デュプレックスで最大 6.4TB/秒の集約帯域幅を備えた 128 個の NVLink 4 ポートを提供します。
最適化されたアーキテクチャと高速相互接続のおかげで、グレースのパフォーマンスも記録的な高さになることが約束されています。 NVIDIA が公開した暫定的な数値によると、単一の Grace ダイで 370 SPECrate2017_int_base ポイント、144 コアのデュアル ダイ アセンブリで 740 ポイントについて話しています。これは、微妙なプラットフォームの最適化を行わずに通常の GCC コンパイラを使用しています。後者の数値は、同じく Arm v9 アーキテクチャを使用する 128 コアの Alibaba T-Head Yitian 710 と 64 コアの AMD EPYC 7773X によって示された結果よりも大幅に高くなっています。
2022-08-21 03:51:49
著者: Vitalii Babkin