Petit à petit, la norme Compute Express Link fait son chemin sur le marché : bien qu'il n'y ait pas encore de processeurs pris en charge, de nombreux éléments d'infrastructure pour la nouvelle interconnexion et les concepts basés sur celle-ci sont déjà prêts - en particulier, de nouveaux contrôleurs et les modules de mémoire sont régulièrement démontrés. Mais la norme elle-même évolue. Dans la version 1.1, dont les spécifications ont été publiées en 2019, les fondations n'ont été que posées.
Mais déjà dans la version 2.0, CXL a reçu de nombreuses innovations qui nous permettent de parler non seulement d'un nouveau bus, mais de tout un concept et d'un changement d'approche de l'architecture serveur. Et maintenant, le consortium responsable du développement de la norme a publié les dernières spécifications de la version 3.0, élargissant encore les capacités de CXL.
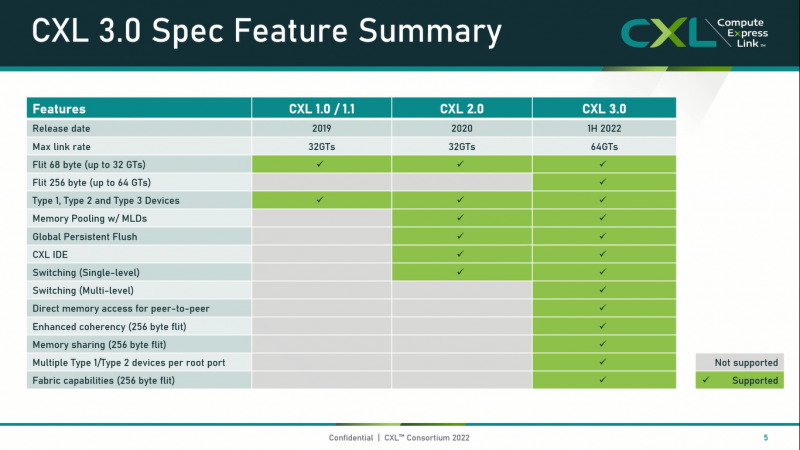
Et pas seulement en expansion: dans la version 3.0, la nouvelle norme a reçu la prise en charge de 64 GT / s, sans augmenter le délai. Ce qui n'est pas surprenant, puisqu'il est basé sur la norme PCIe 6.0. Mais les principaux efforts des développeurs se sont concentrés sur le développement ultérieur des idées de désagrégation des ressources et la création d'une infrastructure composable.
La structure CXL 3.0 elle-même permet désormais la création et la connexion d'appareils multi-têtes, des capacités de gestion d'usine étendues, une prise en charge améliorée des pools de mémoire, des modes de cohérence avancés et la prise en charge de la commutation à plusieurs niveaux. Dans le même temps, CXL 3.0 a conservé la rétrocompatibilité avec toutes les versions précédentes - 2.0, 1.1 et même 1.0. Dans ce cas, certaines des fonctions disponibles ne seront tout simplement pas activées.
L'une des principales innovations est la commutation à plusieurs niveaux. Désormais, la topologie d'une structure CXL 3.0 peut être presque n'importe quoi, de linéaire à en cascade, avec des groupes de commutateurs connectés à des commutateurs de niveau supérieur. Dans le même temps, chaque port racine du processeur prend en charge la connexion simultanée de périphériques de différents types via le commutateur dans n'importe quelle combinaison.
Une autre innovation intéressante était la prise en charge de l'accès direct à la mémoire peer-to-peer (P2P). En termes simples, plusieurs accélérateurs situés, par exemple, dans des racks adjacents, pourront communiquer directement entre eux sans affecter les processeurs hôtes. Dans tous les cas, la protection des accès et la sécurité des communications sont assurées. De plus, il est possible de diviser la mémoire de chaque appareil en 16 segments indépendants.
Dans le même temps, une organisation hiérarchique des groupes est prise en charge, au sein de laquelle la cohérence du contenu de la mémoire et des caches est assurée (l'invalidation est fournie). Désormais, en plus de l'accès exclusif à la mémoire du pool, l'accès partagé par plusieurs hôtes à un bloc de mémoire à la fois est également disponible, de plus, avec un support matériel pour la cohérence. La mutualisation n'est plus laissée à un logiciel tiers, mais s'effectue via un responsable d'usine standardisé.
La combinaison de nouvelles fonctionnalités porte l'idée de séparer la mémoire et les ressources de calcul à un nouveau niveau : il est désormais possible de construire des systèmes où un seul pool de mémoire connecté à la structure CXL 3.0 (Global Fabric Attached Memory, GFAM) existe réellement. séparément des modules de calcul. Dans le même temps, la possibilité d'adresser jusqu'à 4096 points de connexion se heurtera plutôt aux limites physiques de l'usine.
Le pool peut contenir différents types de mémoire - DRAM, NAND, SCM - et être connecté à la puissance de calcul à la fois directement et via des commutateurs CXL. Un mécanisme est prévu pour que les dispositifs eux-mêmes signalent leur type, leurs capacités et d'autres caractéristiques. Une telle architecture promet d'être demandée dans le monde de l'apprentissage automatique, dans lequel les ensembles de données pour les réseaux de neurones de nouvelle génération atteignent déjà des tailles vraiment gigantesques.
Le groupe CXL compte actuellement 206 membres, dont Intel, Arm, AMD, IBM, NVIDIA, Huawei, les principaux fournisseurs de cloud dont Microsoft, Alibaba Group, Google et Meta, ainsi qu'un certain nombre de grands fabricants de matériel de serveur, notamment HPE et DellEMC.
2022-08-02 13:13:46
Auteur: Vitalii Babkin